100万token:Claude现在能记住一整本书了

100万token。
这个数字我反复确认了几遍,去Claude官方看了消息,才打开电脑准备写这篇。
3月13号,Anthropic正式宣布:Claude Opus 4.6和Sonnet 4.6的100万token上下文窗口全面开放。不是beta,不是waitlist,不是"部分用户灰度"——是GA,所有人都能用。
先说这个数字到底意味着什么。
100万token,到底有多大
100万token ≈ 75万字英文,≈ 50万字中文。
不够直观?换算一下:
整套《哈利波特》系列,7本加起来大约108万字英文。100万token能装下其中70%。
或者这么想——15到20本普通小说,一次性塞进去,Claude记得住。
或者一个中型代码库,几万行代码。或者一家公司的全年财报。
之前Claude的窗口是200K token,已经在业界算大的了。这次直接翻了5倍。
额,你说这升级猛不猛。
因为我在OpenClaw上用的模型是Claude,所以我很关心龙虾有没有得到升级。一看对话窗口,果然已经升级到1m,也就是说,我不用再急着/new新窗口,担心上下文超标的问题了,也是美滋滋。

定价不变——这才是真正的重点

上下文窗口变大,通常意味着账单也变大。但Anthropic这次选了一条不太常见的路:
定价不变。没有长上下文溢价。
Opus还是$5/$25 per MTok,Sonnet还是$3/$15 per MTok。
你用100万token跑一次,和用10万token跑十次,每个token的单价一样。
说实话,看到这个的时候我有点意外。因为长上下文对算力的要求明显更高。不加价,要么是Anthropic在技术上做了优化让成本可控,要么是战略性定价——先把用户圈进来再说。
不管原因是什么,对我们用户来说,这是实打实的好消息。
还有一个容易被忽略的升级:媒体上限从每个请求100张图片/PDF页面,提升到了600张。6倍。这意味着你可以把一整份几百页的合同、一本技术文档、或者一年的财务报表,一次性扔给Claude。之前一直有限制,文件数量多的情况下,我都是直奔Gemini,现在就多了个选择了。
跟竞品比,什么水平
话说回来,100万token虽然很能打,但不是业界最大的。拉个横向对比:
- Gemini 2.5 Pro:200万tokens
- Claude Opus/Sonnet 4.6:100万tokens
- GPT-4o:128K tokens
- DeepSeek V3:128K tokens
Gemini在窗口大小上确实领先。但上下文窗口不只是"能装多少"的问题,还有"装进去之后能不能真的用好"。
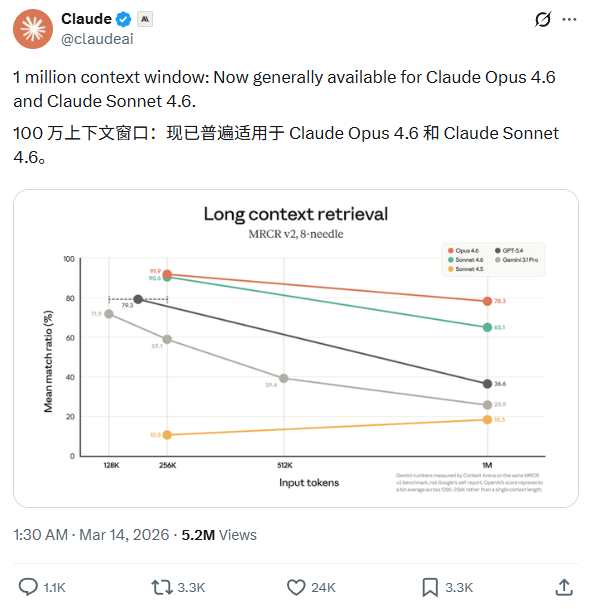
Opus 4.6在MRCR v2基准测试拿到了78.3%的得分——这是目前前沿模型里的最高分。MRCR测的就是模型在超长上下文里找信息、做推理的能力。
换句话说:不只是记得住,还用得好。
我的实际体验

我是Claude Max的付费用户,Gemini Pro订阅。我的AI助手皮皮虾跑在Opus和Sonnet 4.6上面。
说实话,100万token对我的日常工作流影响是真实可感的。
长文翻译——以前翻译一篇长文章需要分段喂,因为超过上下文窗口Claude就会"忘记"前面的内容,翻到后面风格突然变了。现在一整篇丢进去,上下文连贯性好了太多。
代码审查——我让皮皮虾帮我审查代码库的时候,之前只能一个文件一个文件看,它理解不了整个项目的架构。现在可以把几万行代码一起塞进去,它终于能看到"全貌"了。这个差距是质变级的。
内容pipeline——我做YouTube、做多平台分发,素材量很大。之前需要反复给Claude补充背景信息,现在一个对话里就能装下所有素材和历史讨论,效率提升非常明显。
打个不太恰当的比方:之前的Claude像一个记忆力一般的实习生,你每次交代任务都得把前情提要重新讲一遍。现在的Claude像一个跟了你半年的助手,所有背景它都记得。
这波升级对普通用户意味着什么
你可能会想:我又不写代码,也不审查合同,100万token跟我有什么关系?
关系大了。
几个最直接的场景:
读书。你可以把一整本书丢给Claude,然后问它任何问题。“第三章那个案例和第七章的结论矛盾吗?““帮我找出书里所有关于XX的论点。“以前做不到,因为装不下。现在能了。
整理资料。考试复习、论文写作、项目研究——把所有参考资料一次性喂进去,让Claude帮你梳理脉络、找到交叉引用、生成大纲。
工作对话。把过去几个月的会议纪要、邮件、文档全扔进去,问Claude"我们Q1的核心决策有哪些变化”。它能给你一个连贯的答案,而不是只看最后几条消息。
Anyway,100万token不是给极客炫技用的。它解决的是一个非常朴素的问题:让AI真正理解你在说什么,而不是每次对话都从零开始。
传播数据——行业反应有多大
这条消息的传播数据也挺能说明问题。
Anthropic官方推文:520万浏览。Hacker News上直接冲到1110分的顶帖。Reddit、Cursor论坛、LinkedIn、Windows Report等各种渠道都在报道。
 这种量级的关注度,说明100万token不只是一个技术参数的更新,是一个让整个行业觉得"事情不一样了"的节点。
这种量级的关注度,说明100万token不只是一个技术参数的更新,是一个让整个行业觉得"事情不一样了"的节点。
值得关注的企业案例
Anthropic在公告里引用了一批企业客户的反馈,简单列几个:
- Physical Superintelligence用100万上下文做物理研究,一次性加载大量实验数据
- GC AI用来处理法律合同——合同这种东西动辄几百页,之前没法整体分析
- Cognition(就是做Devin的那家)用来做代码审查,整个代码库级别的review
- Hex用来做数据分析,把海量数据集和查询历史一起扔进去
这些场景有一个共同点:信息量大、上下文依赖强、之前不得不分段处理。100万token让"一次看完"变成了可能。
100万token。不加价。 600张媒体上限。前沿模型最高的长上下文得分。
这次更新没有什么花哨的新功能名字,没有炫酷的demo视频。但它解决的是AI最根本的问题之一——记忆。
一个能记住一整本书的AI,和一个只能记住最后几页的AI,是完全不同的东西。
工具的价值不在于参数多大,在于你用它能做成什么事。
感谢观看。